DeepSeek hype
At first glance, it seems like they just utilized all best practices.
My friend recently told me that i have an ability to rapidly find "real life bugs" in everything i try independently without any bias.
It is funny how "americanized" and "tiktok-like" it became after i prompted it to write using very basic language.
What is that hard line break after "for"? And the dollar sign, because of which it formatted the next token sequence in one word via latex. And it is 0-shot
Base model
Anyways, here's how architecture looks like:
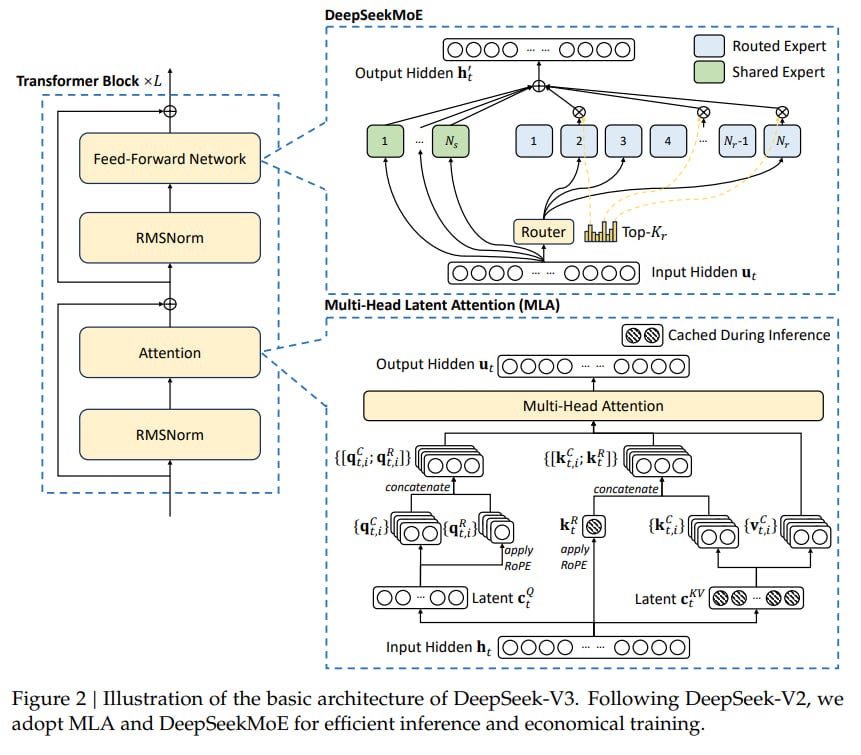
According to information we have(if it's true). They used H800, which is export-restricted version of H100, and they state it required 2.788M GPU-Hours on that for full training, in dollars it's $5.576M at a H800 rental price of $2 per hour. comparing with Meta's $60M.
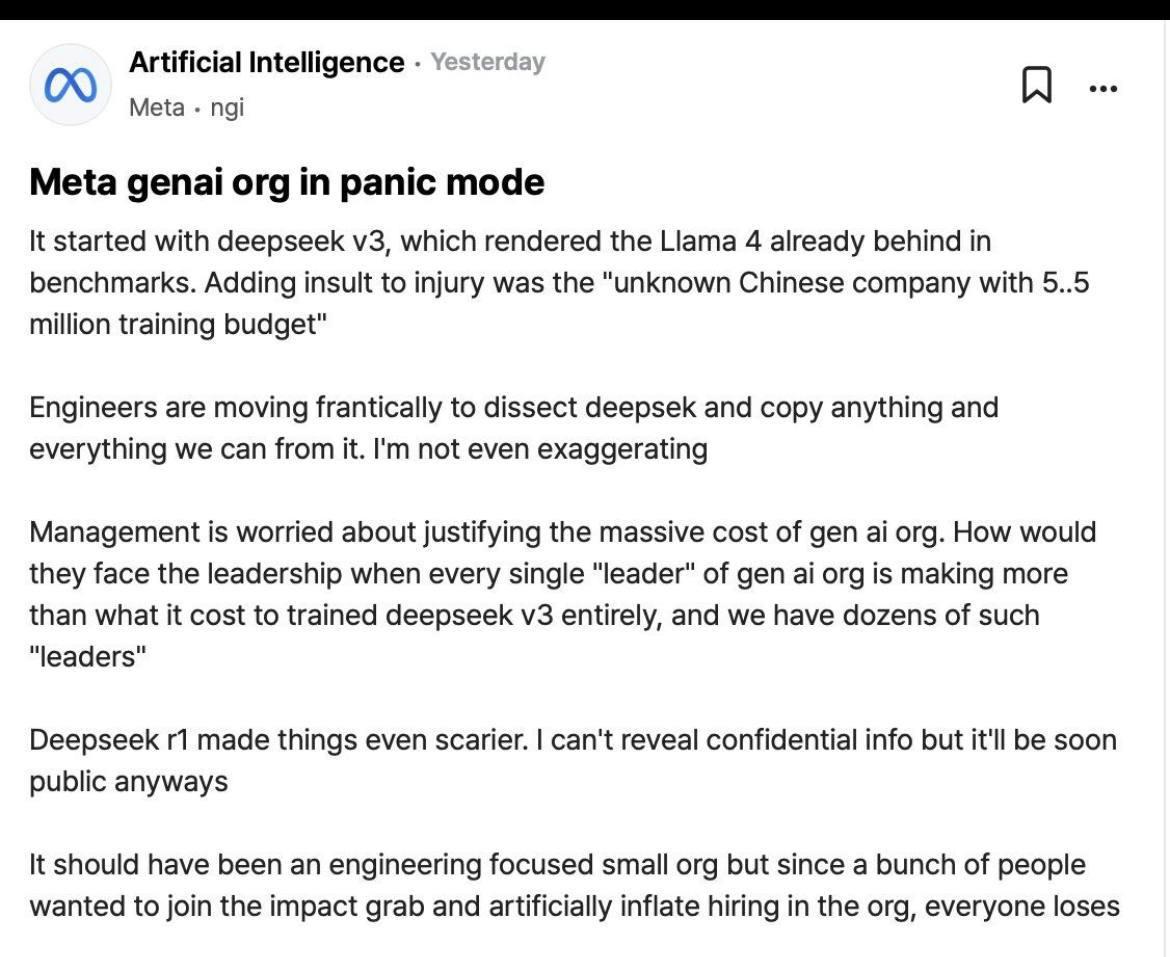
Of course it raised some concerns between Zuck's employees:
Reasoning
So there are 2 models, DeepSeek-R1-Zero and DeepSeek-R1, built on DeepSeek-V3-Base.
R1 zero was trained with GRPO, a variant of PPO.
It has potential to perform exceptionally well at reasoning tasks without labeled SFT set. Makes sense, base model was trained on 14.8 trillion tokens and it is evaluated on reasoning tasks, not on general chatting.
DeepSeek developed two key models: Zero and R1. While Zero performs well overall, it has some limitations:
- Tends to get stuck in repetitive patterns
- Sometimes mixes different languages
- Can produce text that's difficult to read
DeepSeek-R1 introduced improvements through a multi-stage training process:
- Cold Start Phase
- Initial training on thousands of Chain-of-Thought (CoT) examples
- Creates a better foundation before reinforcement learning
- Reasoning-focused RL
- Uses the same reasoning-oriented reinforcement learning as in Zero
- Supervised Fine-Tuning (SFT)
- 600k reasoning-focused examples
- 200k general (non-reasoning) examples
- Final Phase
- Additional round of reinforcement learning
"OpenAI, has complained that rivals, including those in China, are using its work to make rapid advances in developing their own artificial intelligence (AI) tools." source
In conclusion, their idea was to parse whole internet, and now they cry about "bad chinese" being reasonably better. I think DeepSeek made a really good leap in reasoning, but overall thing around it, is pretty overhyped.
links: DeepSeek-V3 DeepSeek-R1
links for other inventions:
multimodal model. text+image input output Janus 1B & 7B
llava-style VLM with MoE. text+image input; out: text DeepSeek-VL2