Titans: Memory for attention
New paper about adding long-term memory for transformer architecture.
Gentlemen from Google Research are taking their inspirations from neuropsychology literature and define memory as a "neural update caused by an input", and define learning as a "process for acquiring effective and useful memory, given an objective".
They compare linear transformers with linear RNNs as more of like matrix-valued memory and vector-valued memory.
Architecture
They state that "an event that is surprising is more memorable for humans" and inspired by this, they admit it can be gradient with respect to the input. The larger the gradient is, the more different input data is from the past data. They call it momentary surprise and for the sake of not hitting local minima, they additionally including past surprise, which indicates the surprise amount of a very recent past.
On top of that they are adding weight decay mechanism that decides how much information should be forgotten. They will call it contextual memory later in their illustrations. In addition, they use persistent memory, which is set of learnable, but input-independent parameters.
They introduce 3 types of architecture designs:
- MAC (Memory as a Context) - long term memory used as context for current attention
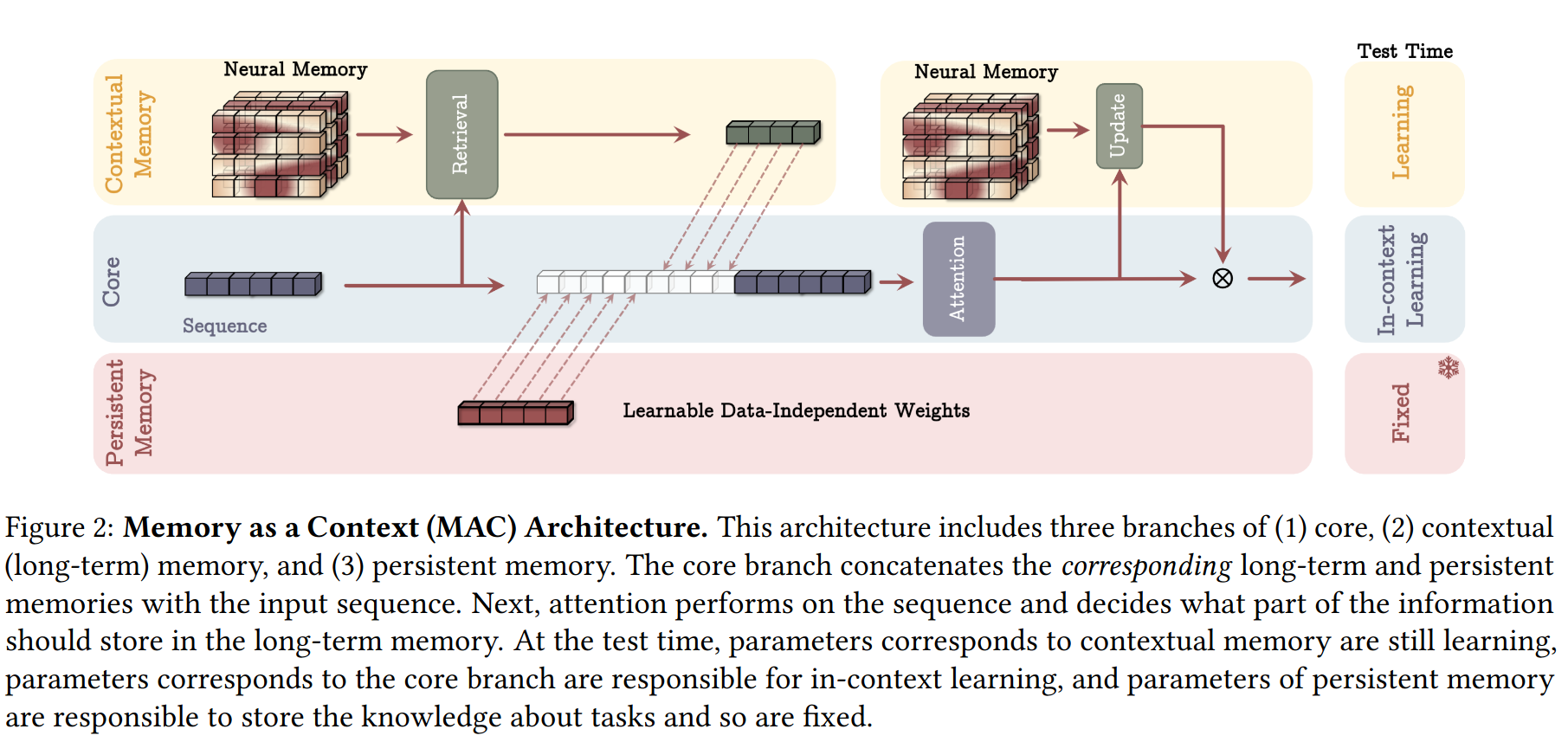
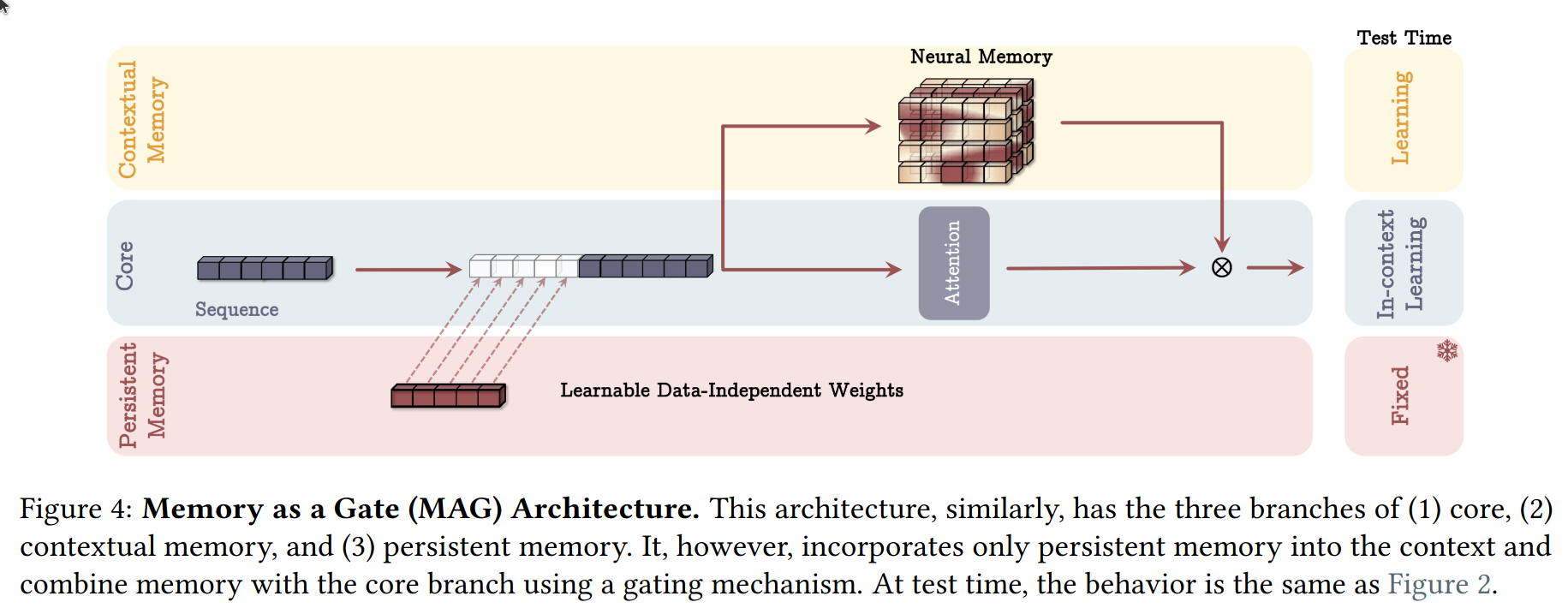
- MAG (Memory as a Gate) - same gating mechanism as in LSTM
- MAL (Memory as a Layer) - all memory connected as a layer in network
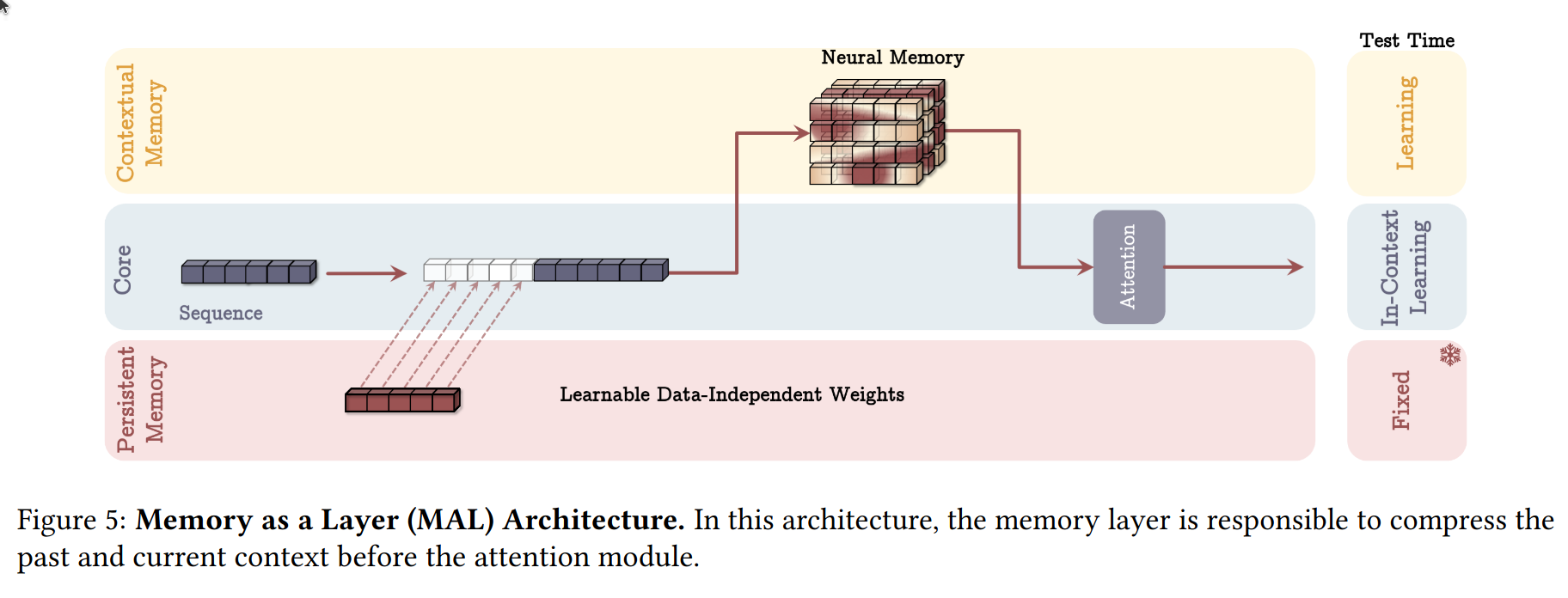
In their experiments they also include LMM. It's made for evaluating memory in MAL design, they use similar architecture as in Hungry Hungry Hippos, but they replace sequence model with neural memory module(LMM). Since each part of memory system should work independently, they treat it as a standalone model, even without short-term memory.
Benchmarks look quite good, beating RMT.
I see they treat linear attention like it's just one non-linear layer "MLP", so this generalizes gated delta networks, which is SOTA there. I think it's nice to use gradients as means of updating the memories before you sum the key value map and do associative scan with gate or whatever. If everything is leading to train at test time then it's good i guess.
On the other hand, paper has some implicit negative results. Maybe they tried something and it didn't work as planned?
Anyways, they promised to publish a code soon, but there is already an implementation by lucidreams(Phil Wang) available in Pytorch.